
- Sean Rooney
- Luis Garcés Erice
- et al.
- 2021
- BigData Congress 2021
Pathfinder: Building the Enterprise Data Map
Overview
Pathfinder for Data Compliance
The challenge
Successful enterprise data processing systems have a tendency to grow out of their well managed walled-gardens. This happens because they need additional resources and tools found outside the garden, e.g. offered by a Cloud provider, or because they start to connect into other internal and external enterprise systems. Traditional metadata catalogs do not scale well to handle this organic growth, as they depend on static and predefined processes to manage and curate data within some well defined perimeter. This makes enterprise data management an intractable problem as the data is constantly been moved and processed between these heterogeneous distributed systems by a large number of independently managed tools and users.
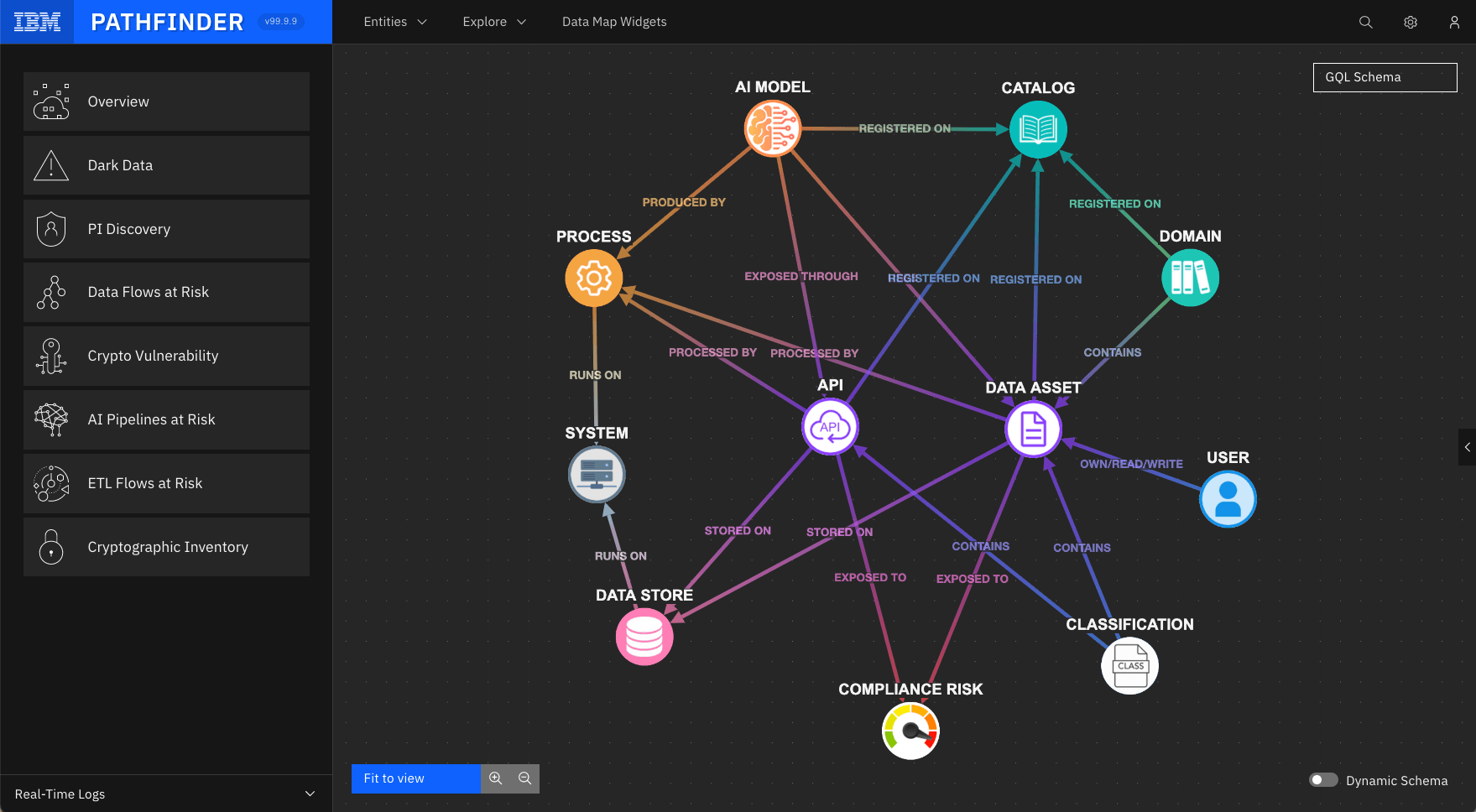
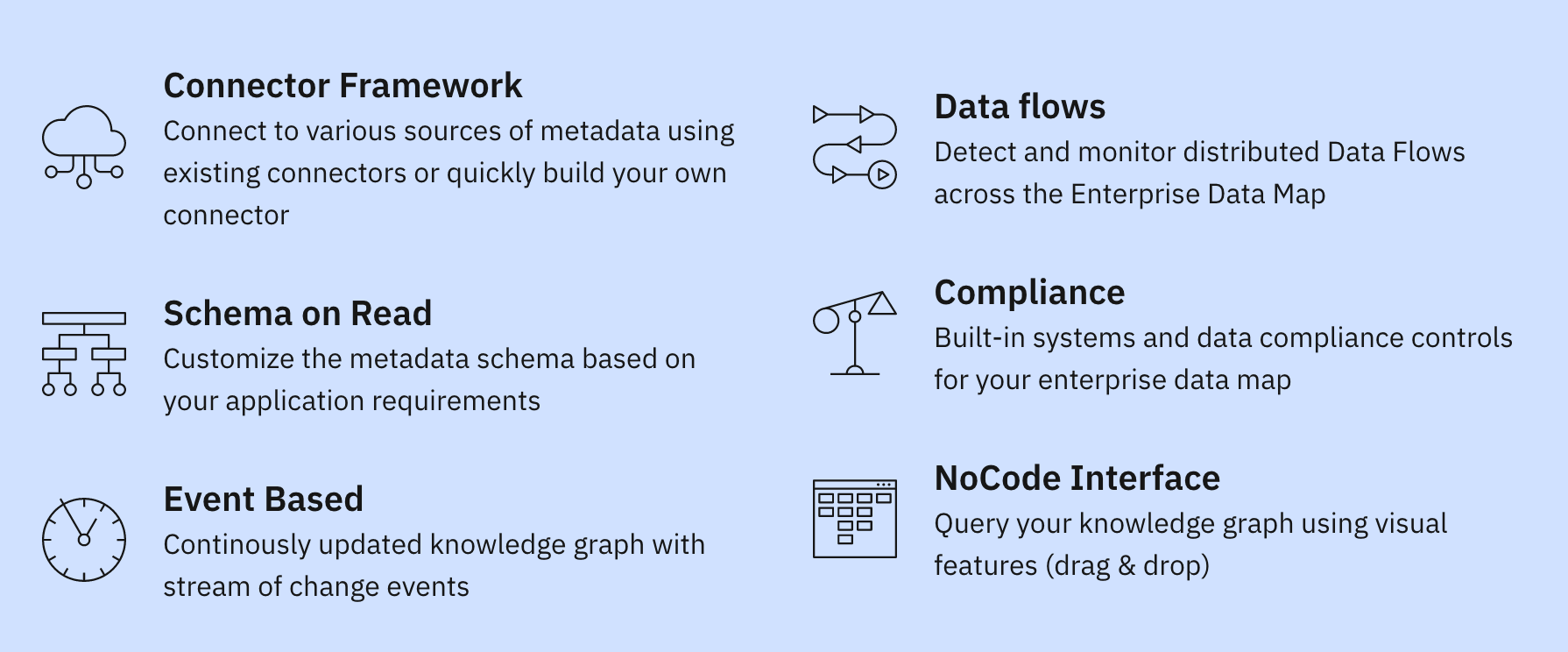
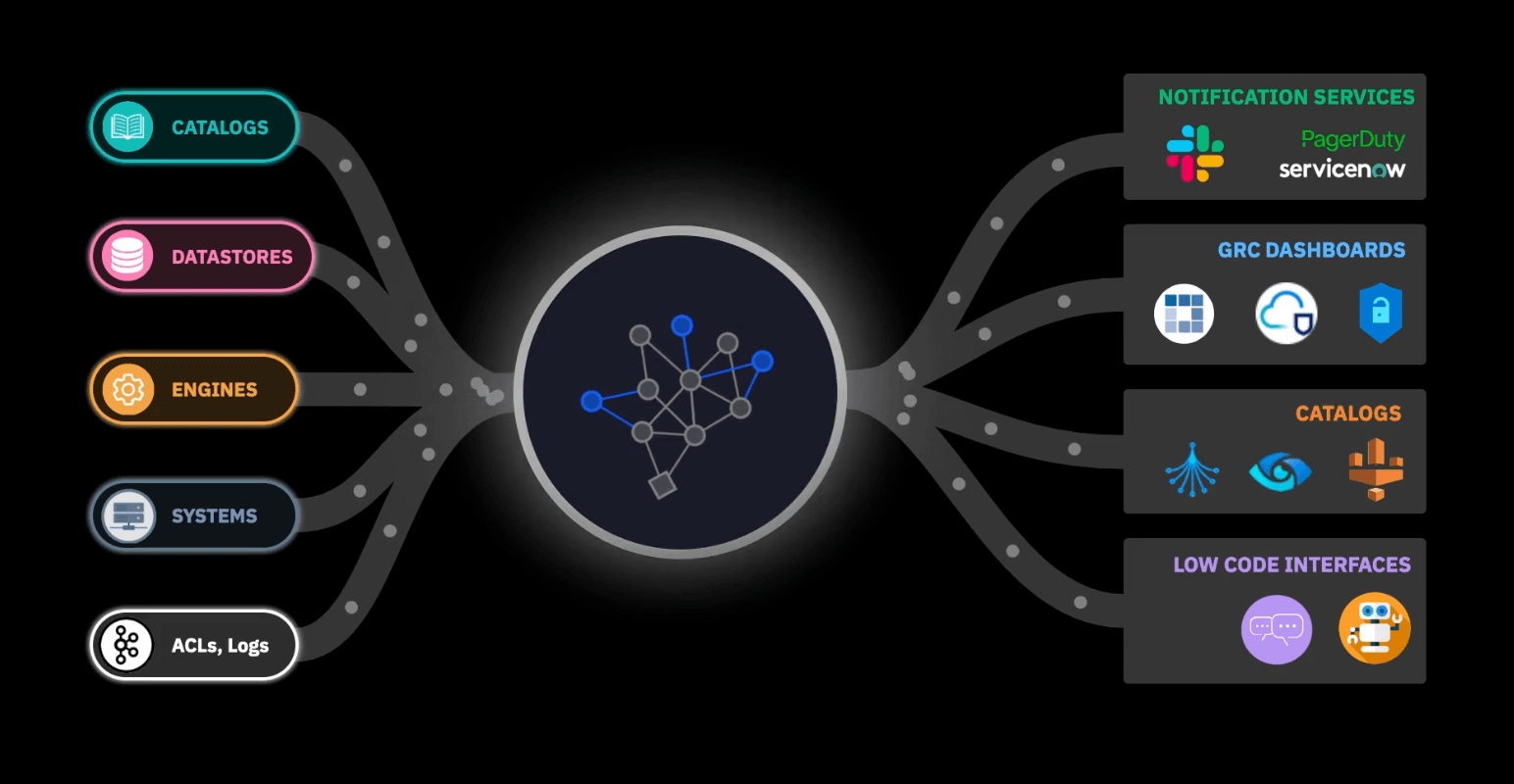
Significant value can be enabled by gathering, linking and enriching metadata at enterprise scale allowing cost reduction through, for example identifying cold data, removing unnecessary data duplication or better scheduling of data intensive workflows. New value added services can also be introduced with the guarantee that sensitive data is being used in the way it is intended and being properly governed and protected. Pathfinder is an event-driven data observability system that collects metadata from multi-cloud and on prem environments in order to build a complete map of Enterprise data. The data map is represented as a Knowledge Graph that is further enriched with Graph Machine Learning techniques. This enables for instance the discovery of hidden data assets and their classification, the detection of implicit relationships between data assets, and potential data transfers that may not be captured in logs or catalogues. The enriched knowledge graph can be consumed by third party systems such as GRC applications and notification services.
The Enterprise DataMap
The metadata is extracted from source systems into a location where is is gathered, linked and enriched. This can be thought of as analogous to a data lake in a big data system. As most of the value in the metadata is gained through understanding the complex relationships between entities, this is stored as a graph that allows the entire data of the enterprise to be mapped, such that questions about where data is stored, how are those storage system protected, where does data flow can be answered at the level of the enterprise rather than at a single isolated processing platform. Metadata stored in the graph can be enriched just as in a classic data lake by multiple independent processes that can add new properties, relationships and entities that were not in the raw data, e.g. that a set of data pipelines resemble each other, which can possibly be merged enabling cost saving, or data with a certain classification is not being properly handled, thus exposing the organization to potential compliance issues. The knowledge graph is open and scalable meaning that advanced analytics and machine learning techniques can be applied to it for various purposes.
Getting started with Pathfinder
Please reach out to us at pathf@zurich.ibm.com
Publications
- Daniel Bauer
- Florian Froese
- et al.
- 2021
- Big Data Research
- Luis Garcés-Erice
- Sean Rooney
- et al.
- 2020
- CLOUD 2020
- Sean Rooney
- Daniel Bauer
- et al.
- 2019
- CIC 2019
- Daniel Bauer
- Chris Giblin
- et al.
- 2022
- Middleware 2022
- Gero Dittmann
- Christopher Giblin
- et al.
- 2022
- Big Data 2022
- Florian Fröse
- Daniel Bauer
- et al.
- 2022
- VLDB 2022
- Christopher Giblin
- Sean Rooney
- et al.
- 2021
- BigData Congress 2021