Mining biomedical data
In recent years, the number of biomedical publications freely available in the literature has grown enormously, resulting in a rich source of untapped new knowledge. However, most biomedical data is buried in the form of unstructured text, and their exploitation requires expert knowledge and time-consuming manual curation of published articles. Hence the development of novel methodologies that can automatically analyze textual sources, extract facts and knowledge, and produce summarized representations that capture the most relevant information in a timely fashion.
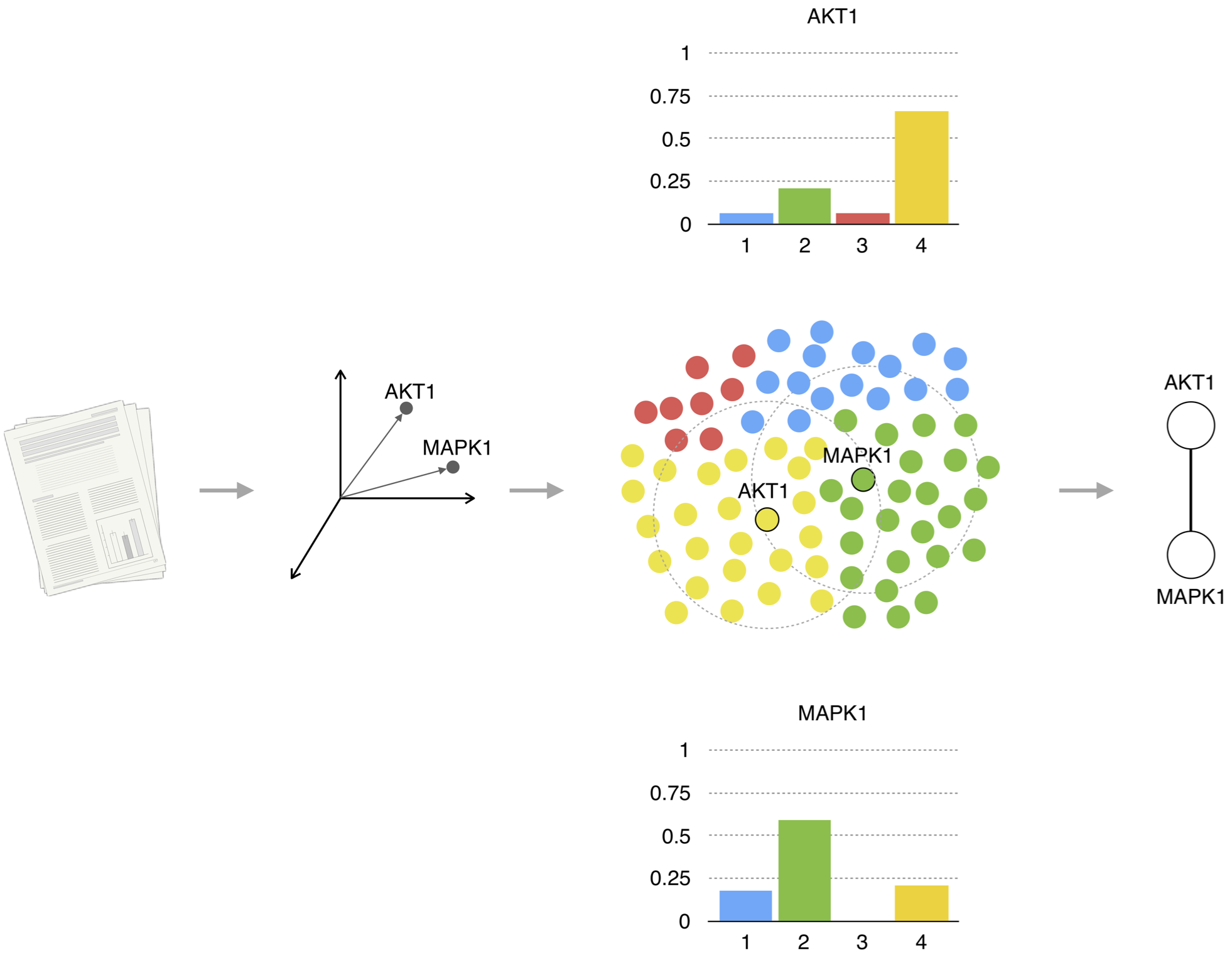
INtERAcT represents a novel approach to infer interactions between molecular entities extracted from the literature using an unsupervised procedure that leverages recent developments in automatic text mining and analysis. INtERAcT implements a new metric that acts on the vector space of word representations to estimate an interaction score between two molecules.
References
“INtERAcT: Interaction Network Inference from Vector Representations of Words,”
Matteo Manica et al., arXiv:1801.03011, 2018.
“Context-specific interaction networks from vector representation of words,”
Matteo Manica et al., Nature Machine Intelligence 1(4), 181–190, 2019.
Upload pre-trained word vector representations and a protein list to estimate networks.
Questions?
Ask the expert

Matteo Manica
IBM Research Scientist

Joris Cadow
IBM Data scientist
Funding
This research is funded by the PrECISE EU project
