

- Jan van Lunteren
- 2023
- PACT 2023
Snap machine learning
A library that provides high-speed training of popular machine learning models on modern CPU/GPU computing systems.
Overview
Optimizing Machine Learning
-
Accelerate popular Machine Learning algorithms through system awareness, and hardware/software differentiation
-
Develop novel Machine Learning algorithms with best-in-class accuracy for business-focused applications
AI in Business – Challenges
Snap Machine Learning (Snap ML in short) is a library for training and scoring traditional machine learning models. Such traditional models power most of today's machine learning applications in business and are very popular among practitioners as well (see the 2019 Kaggle survey for details). Snap ML has been designed to address some of the biggest challenges that companies and practitioners face when applying machine learning to real use cases. These challenges are listed below.
Speed
- Train and re-train on new data online
- Large parameter, model searches
- Make fast decisions
Efficiency
- Use resources judiciously
- Less resources means less $
- On-prem and in the cloud
Accuracy
- Make accurate decisions or predictions
- Cost savings (e.g. card fraud), higher revenue (e.g. portfolio allocation)
Data Size
- Learn from all available data
- More data, better models, higher accuracy
- Handle big data efficiently
Snap ML is
Fast
Multi-threaded CPU solvers as well as GPU and multi-GPU solvers that offer significant acceleration over established libraries.
Scalable
Distributed solvers (for generalized linear models currently) that scale gracefully to train TB-scale datasets in mere seconds.
Accurate
A novel gradient boosting machine that achieves state-of-the-art generalization accuracy over a majority of datasets.
Resource-efficient
Ability to complete large training jobs in less resources, with high resource utilization.
Consumable
Familiar Python scikit-learn APIs for single-server solvers and Apache Spark API for distributed solvers.
Supported Machine Learning Models
Generalized Linear Models
State‐of‐the‐art solvers on multi‐core, multi‐socket CPUs. Twice‐parallel, asynchronous stochastic coordinate descent (TPA‐SCD) for training linear models on GPUs.
- Linear Regression
- Logistic Regression
- SVM
Tree-based Models
Memory‐efficient breadth‐first search algorithm for training of decision trees, random forests and gradient boosting machines.
- Decision Trees
- Random Forest
Gradient Boosting
Heterogeneous boosting machine that employs multiple classes of base learners, versus only decision trees.
- Boosting Machine
Seamless acceleration of scikit-learn applications
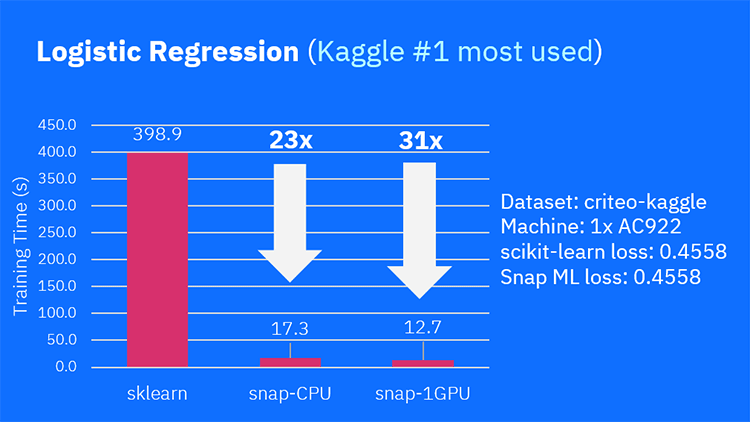
Snap ML offers very powerful, multi‐threaded CPU solvers, as well as efficient GPU solvers. Here is a comparison of runtime between training several popular ML models in scikit‐learn and in Snap ML (both in CPU and GPU). Acceleration of up to 100x can often be obtained, depending on model and dataset.
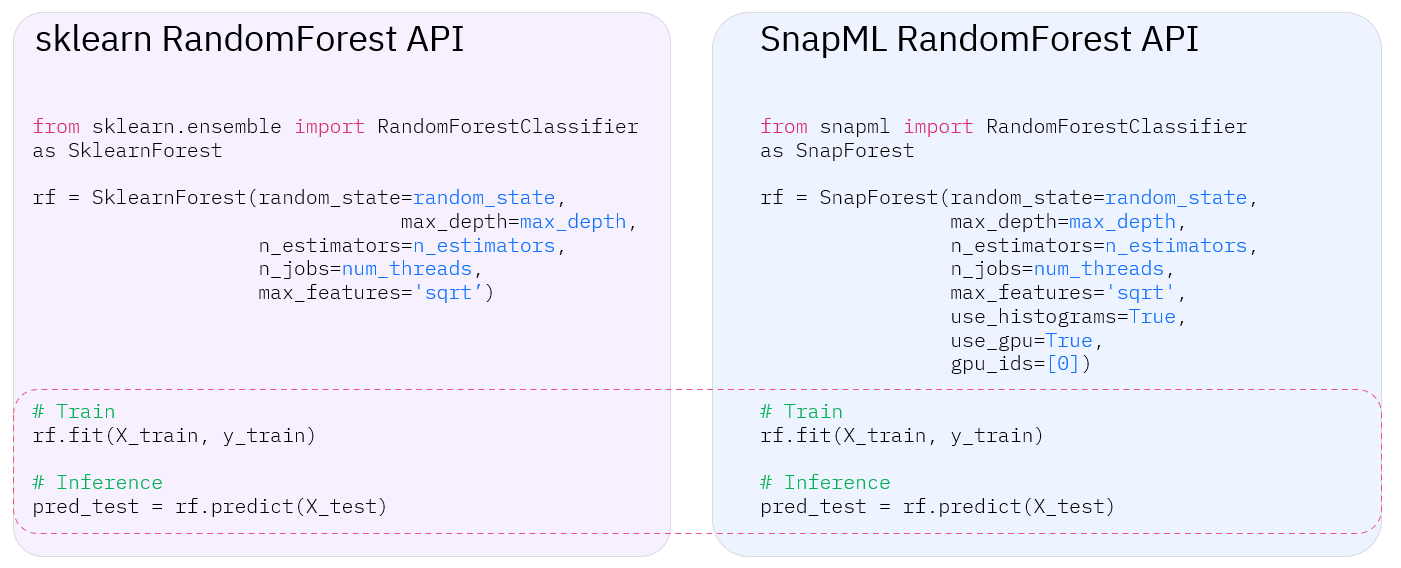
At the same time, the above acceleration is almost seamless to the user. For data scientists using Python, only minimal changes are needed to their existing code to take advantage of Snap ML. Here is an example of using a Random Forest model in both scikit‐learn as well as Snap ML.
Gradient Boosting Machine
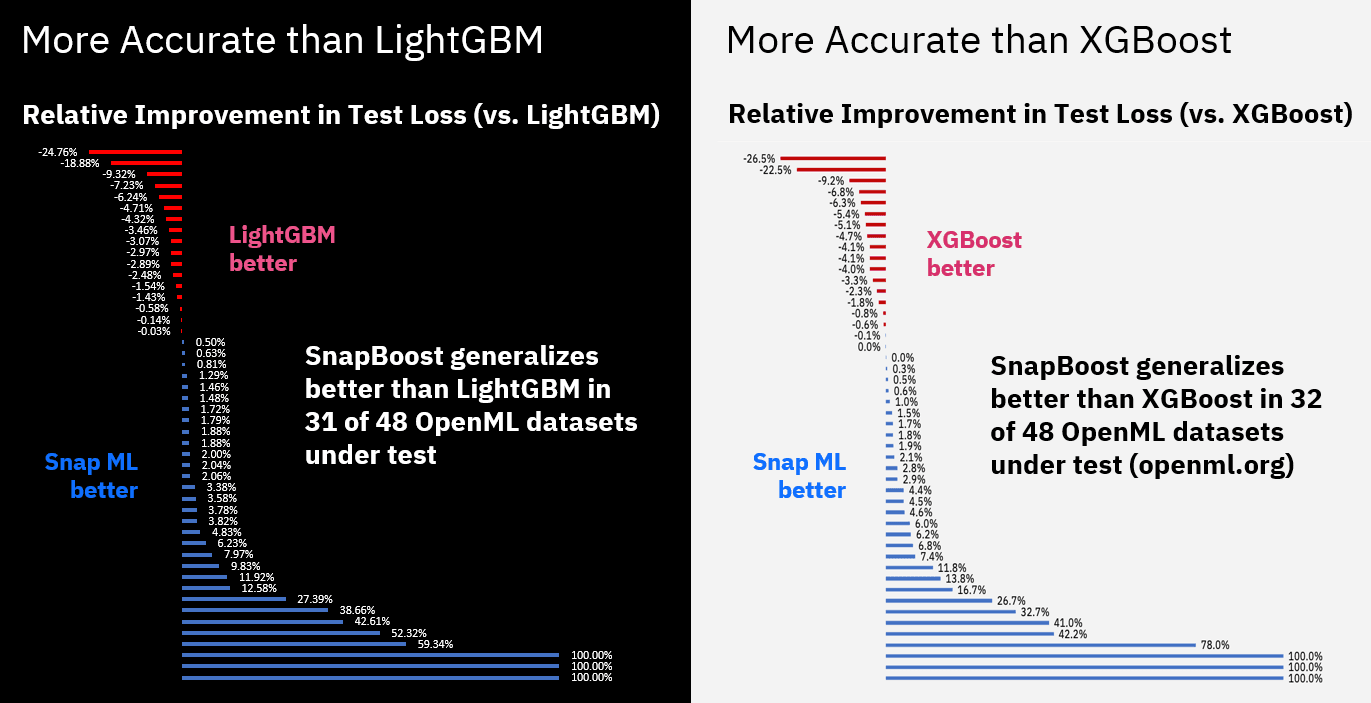
Gradient Boosting models comprise an ensemble of decision trees, similar to a random forest (RF). Although Deep neural networks achieve state-of-the-art accuracy on image, audio and NLP tasks, on structured datasets Gradient Boosting usually out-performs all other models in terms of accuracy. Some of the most popular Boosting libraries are XGBoost, LightGBM and CatBoost. Snap ML introduces SnapBoost, which targets high generalization accuracy through a stochastic combination of base learners, including decision trees and Kernel ridge regression models. Here are some benchmarks of SnapBoost against LightGBM and XGBoost, comparing accuracy across a collection of 48 datasets. SnapBoost learns a better model in about 2-out-3 of the datasets tested.
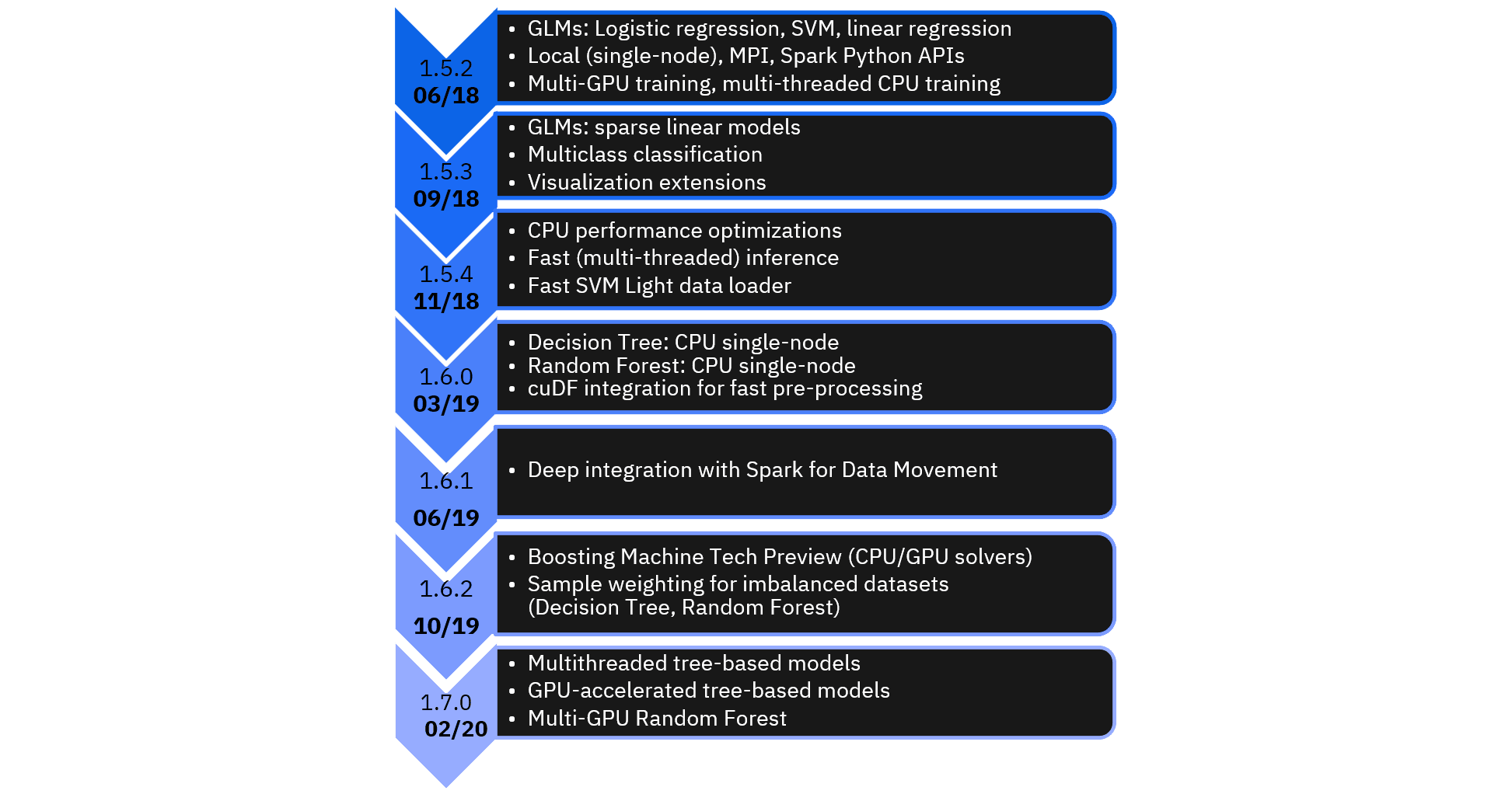
OpenML (www.openml.org) is a platform for collaborative data science. Snap ML’s Gradient Boosting was benchmarked against XGBoost and LightGBM using 48 binary classification datasets from OpenML. Hyper-parameter tuning and generalization estimation was performed using 3x3 nested cross-validation. Snap ML provides best-in-class accuracy for a majority of datasets.Snap ML Evolution
Where to get / How to try Snap ML
-
pip install snapml
-
Support for: Linux/x86, Linux/Power, Linux/Z, MacOS, Windows
-
GPU support available for Linux
-
Documentation: https://snapml.readthedocs.io/
-
Example Jupyter notebooks: https://github.com/IBM/snapml-examples
Publications
- 2023
- CLOUD 2023
- Nikolaos Papandreou
- Jan Van Lunteren
- et al.
- 2023
- ISCAS 2023
- Malgorzata Lazuka
- Thomas Parnell
- et al.
- 2022
- CLOUD 2022
- Georgios Damaskinos
- Celestine Mendler-Dünner
- et al.
- 2021
- AAAI 2021
- Thomas Parnell
- Andreea Anghel
- et al.
- 2020
- NeurIPS 2020
- Dimitrios Sarigiannis
- Thomas Parnell
- et al.
- 2020
- AAAI 2020
- Nikolas Ioannou
- Celestine Mendler-Dünner
- et al.
- 2019
- NeurIPS 2019



