
- 2023
- CMD 2023
Overview
Redefining the future of computing
AI has become an essential part of our daily life. The processing of data in such a system is based on Deep Neural Network architectures. As the number of parameters in such networks continues to grow exponentially, it is of utmost interest to find new hardware solutions that are more power-efficient and better adapted to the specific signal processing operations of interest.
In the neuromorphic devices and systems team, we tackle this exciting problem by exploring new materials and devices that accelerate Deep Neural Network inference and training. The compatibility with existing silicon CMOS technology is of utmost importance.
Research areas
Neuromorphic architectures
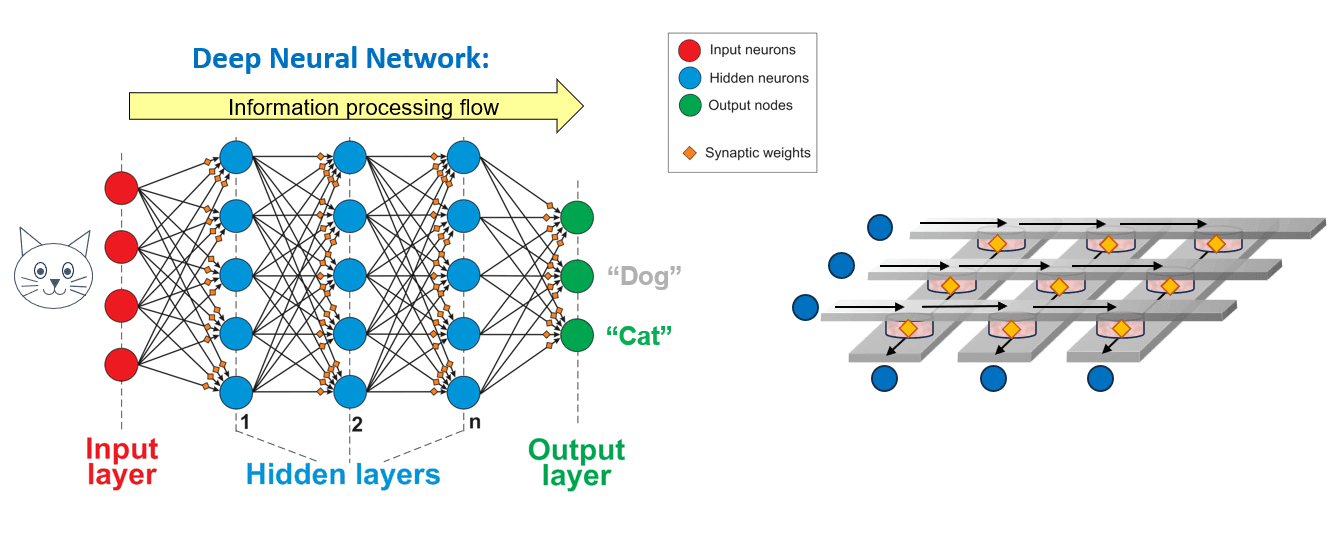
The performance and power-efficiency of the execution of Artificial Intelligence suffers from the large mismatch between the neural network architecture and that of the computing hardware. By better mapping the hardware implementation to the neural network architecture, considerable improvements can be obtained. The main part of the compute effort is related to calculating the communication between the neurons. Each signal is weighted (multiplication), and all weighted signals are summed at the receiving neuron (accumulation). For the connection between two layers of neurons in the network, this is a vector-matrix multiplication.
Electrical memristive devices arranged in crossbars arrays perform exactly this operation. The voltage applied on a memristor generates a current according to Ohms law (multiplication) and all resulting currents are collected into one output wire obeying Kirchhoff’s law (accumulation). The resulting vector-matrix multiplication directly represents the synaptic operation in a neural network.
The memristors in the crossbar represent the weights of the neural network. The resistance is programmed with voltage pulses (~1V) and read with smaller signals (~0.1V) that do not alter the resistance value. Hence, such devices maintain the programmed state, which makes them memristive elements. For neural network inference, it is important that the devices keep their state over time, also after many readings. For training, the resistance change must be well-behaved, ideally linear and symmetric. By applying more advanced training algorithms, such as TikiTaka, the memristive device requirements can be relaxed.
At IBM Research Europe – Zurich, we are pushing the state-of-the-art of such devices and circuits based on filamentary oxides, ferroelectric effects and phase-change materials. In the Neuromorphic Devices and System group, we focus on the first two. This work is performed in collaboration with IBM Research Watson lab and the Albany Nanotech Center.
Left: Deep Neural Network architecture with neurons interconnects through synaptic weights. Right: Electrical crossbar array with memristive devices as the synaptic weights, showing the connectivity between two neuron layers.Analog computing devices
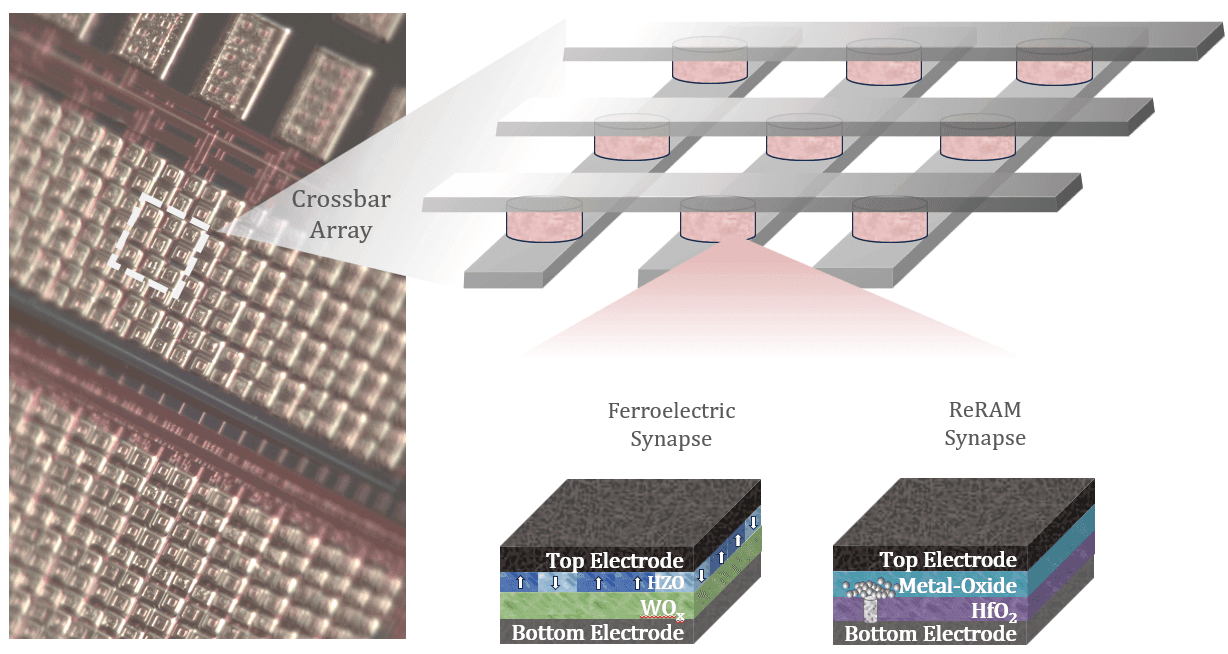
Several concepts exist for realizing the memristive synaptic weight elements. In the Neuromorphic Devices and Systems team, we focus on ferroelectric structures for neural network inference and resistive RAM (ReRAM) devices for training.
The resistance of the ferroelectric devices depends on the polarization orientation of the domains in the ferroelectric layer, CMOS compatible zirconium-doped hafniumoxide (HZO).
The ReRAM structures are based on a bi-layer structure of a metal-oxide and hafniumoxide. The resistance of this type of devices is defined by an exchange of oxygen vacancies between a filament in the hafniumoxide and the metal-oxide.
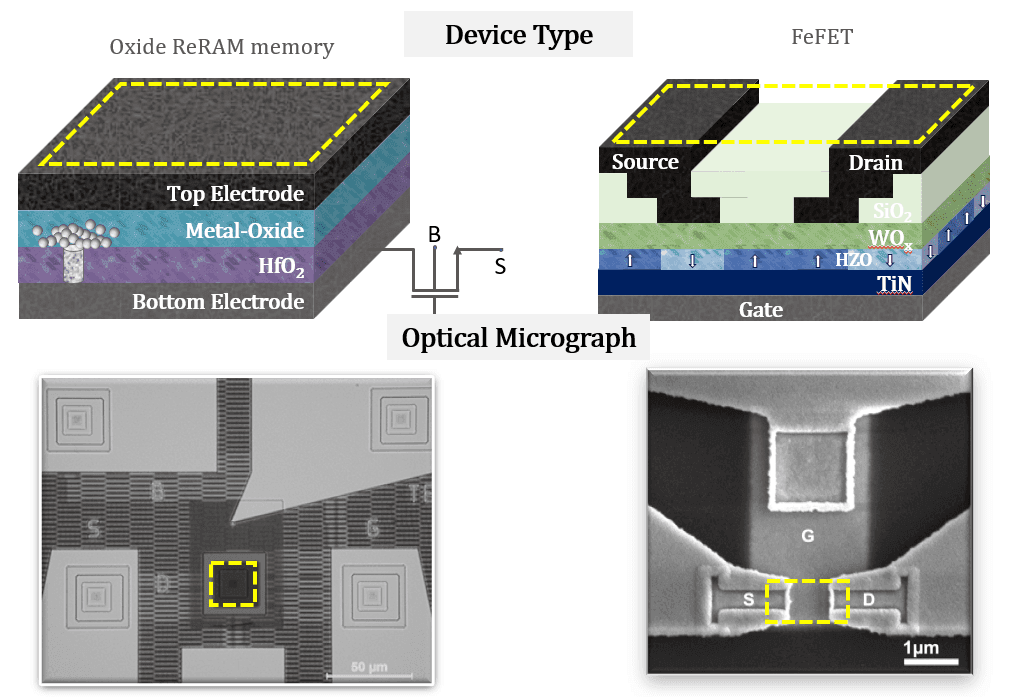
Optical micrograph of a chip with integrated crossbar arrays of ReRAM and Ferroelectric based artificial synapse.Schematic and optical micrograph of an 1T - ReRAM and an FeFET device, respectively.New materials for future computing systems
The continuous advancement of silicon technology relies on device size scaling, new materials, device geometries and functionalities. The activities of the Neuromorphic Devices and Systems group addresses all these aspects, the memristive devices are an excellent example. We combine new materials in novel device geometries to validate a new functionality – analog non-volatile resistive device for neuromorphic computing. Strong focus is on device scaling and CMOS compatibility as these are essential properties for the co-integration in existing technology.
The detailed understanding of the materials properties and interface physics is critical for improving device specifications. We apply a wide range of characterization techniques, device measurements, and modelling software to unravel the physical processes in our devices.
Ferroelectic materials and metal-oxides are of interest for neuromorphic computing but also for advancing the performance of digital CMOS technology.
Externally funded projects
European Union/SERI funded
BeFerroSynaptic - BEOL technology platform based on ferroelectric synaptic devices for advanced neuromorphic processors
MANIC - Materials for Neuromorphic Circuits
Memscales - Memory technologies with multi-scale time constants for neuromorphic architectures
PHASTRAC - Phase Transition Materials for Energy Efficient Edge Computing
TOPOCOM - Topological solitons in ferroic materials and their application in unconventional computing
SNF funded
ALMOND - Advanced Learning Methods On Dedicated nano-Devices
Unico - Unsupervised spiking neural networks with analog memristive devices for edge computing
Completed projects
Dimension - Directly Modulated Lasers on Silicon
NAPRECO - Novel Architectures for Photonic Reservoir Computing
Nebula - Neuro-augmented 112Gbaud CMOS plasmonic transceiver platform for Intra- and Inter-DCI applications
PHOENICS - Photonic Enables Petascale In-Memory Computing with Femtojoule Energy Consumption
PHRESCO - PHotonic REServoir Computing
plaCMOS - Wafer-scale, CMOS integration of photonics, plasmonics and electronics devices for mass manufacturing 200Gb/s NRZ transceivers towards low-cost Terabit connectivity in Data Centers
PlasmoniAC - Energy- and Size-efficient Ultra-fast Plasmonic Circuits for Neuromorphic Computing Architectures
Postdigital - New generation of scientific, industrial leaders in the digital age
ULPEC - Ultra Low Power Event-Based Camera
Publications
- Donato Francesco Falcone
- Youri Popoff
- et al.
- 2023
- MRS Spring Meeting 2023
- 2023
- MRS Spring Meeting 2023
- Crossbar operation of BiFeO3/Ce–CaMnO3 ferroelectric tunnel junctions: From materials to integration
- Mattia Halter
- Elisabetta Morabito
- et al.
- 2023
- Journal of Materials Research
- 2023
- MRS Spring Meeting 2023
- Lorenz K. Muller
- Pascal Stark
- et al.
- 2020
- Frontiers in Neuroscience
- Pascal Stark
- Folkert Horst
- et al.
- 2020
- Nanophotonics
- Laura Begon-Lours
- Mattia Halter
- et al.
- 2021
- IEEE J-EDS
Contributors







Related projects

Oscillating Neural Networks
Performing pattern recognition and solving complex optimization problems with coupled oscillator networks.